Ball Contact — What 4 Changes Made It Work
Dev Log #1 · March 22, 2026 · MH-FLOCKE Level 15 v0.4.x
For weeks, the dog walked beautifully but ignored the ball completely. It would stroll past it, around it, occasionally bump into it by accident — but never pursue it. The spiking neural network was learning to walk. It just had no reason to care about a red sphere sitting on the grass.
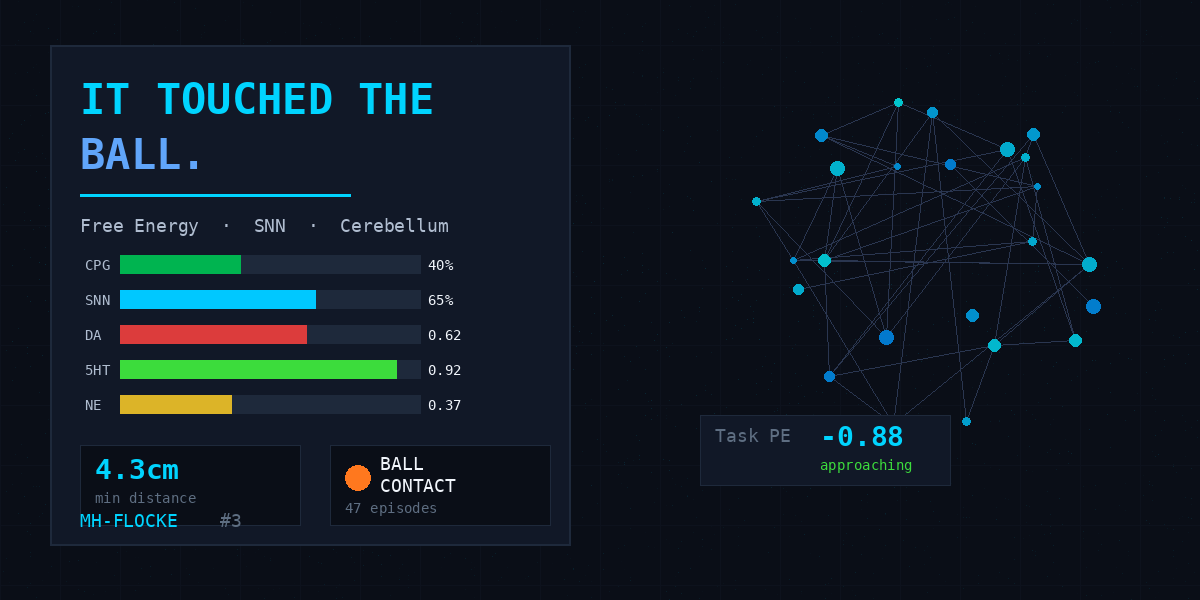
Then, in a single 100k-step training run, everything changed. The Go2 quadruped turned toward the ball, approached it deliberately, and made contact — 294 frames of sustained ball interaction, with a minimum distance of 0.8 centimeters.
No reward shaping. No hardcoded “go to ball” command. Four architectural changes made a biologically grounded system do something that PPO with dense rewards still struggles with.
Here’s what happened.
The Problem: Walking Without Purpose
MH-FLOCKE’s brain runs a 15-step cognitive cycle every simulation tick. Spiking neurons fire. The cerebellum predicts motor outcomes. Central pattern generators produce rhythmic gaits. Neuromodulators shift between exploration and exploitation.
But all of this was happening in a closed loop. The SNN received sensory input that included ball distance and angle — the information was there. The network just had no gradient to follow. Ball distance was one of 80+ input dimensions, buried in proprioceptive noise. The R-STDP learning rule couldn’t distinguish “getting closer to the ball” from random fluctuation.
The system needed a way to feel that the ball matters.
Change 1: Task-Specific Prediction Error
Instead of using a generic reward signal, I introduced a task-specific prediction error (TPE) that directly encodes “how far am I from where I should be”:
TPE = (ball_dist - 3.0) / 3.0
When the dog is 3 meters from the ball, TPE is 0 — neutral. Closer than 3 meters, TPE goes negative — the world is better than expected. Further away, TPE grows positive — something is wrong.
This is not a reward. It’s a prediction error in the Free Energy sense: the system expects to be near the ball (because that’s where interesting things happen), and any deviation from that expectation creates a signal to act.
The critical difference from reward shaping: TPE doesn’t tell the dog what to do. It tells the dog how surprised it should be.
Change 2: Vision Boost
The TPE signal alone wasn’t enough. The SNN has 80+ input neurons, and the ball-related inputs (distance, angle) were getting drowned out by proprioceptive signals — joint angles, velocities, IMU readings. The network couldn’t hear the ball over the noise of its own body.
The fix: when TPE exceeds a threshold (0.05), the last 16 input neurons — the ones carrying sensory/environmental information — get amplified by TPE × 0.5. Higher prediction error means louder sensory input.
This mirrors how biological attention works: when something is unexpected, sensory cortex activity increases. The salience of the stimulus goes up proportional to how wrong your predictions are.
The effect was immediate. The SNN started responding to ball distance changes within the first 10k steps.
Change 3: R-STDP Sign Fix
This was the most embarrassing bug. The R-STDP learning rule combines reward and prediction error:
combined = 0.1 × reward + 0.9 × (−PE)
The minus sign on PE is critical. When the dog approaches the ball, PE decreases (less surprise). The negative of a decreasing value is positive — which means approaching creates positive reinforcement for the synapses that were active during that movement.
The original code had the sign flipped. Approaching the ball was punishing the very synapses that caused the approach. The SNN was literally learning to avoid the ball.
One minus sign. Weeks of debugging.
Change 4: Ball Curriculum
Even with correct gradients, dropping a ball 3 meters away at a random angle is too hard for a system that just learned to walk. The solution: a 5-stage curriculum.
Stage 1 starts the ball at 1.5 meters, directly ahead (0° angle). The dog barely has to turn — just walk forward. When ball_dist_min drops below 0.5 meters, the curriculum advances.
Each stage increases distance and angle: (1.5m, 0°) → (2.0m, 17°) → (2.5m, 23°) → (2.7m, 28°) → (3.0m, 34°).
In the 100k-step run, the dog advanced through two stages. It mastered straight-ahead approach, then learned to turn slightly before approaching. The curriculum let the SNN build on what it already knew.
Results
The numbers from the run:
- 0.8 cm minimum ball distance — the dog essentially touched it
- 294 contact frames — sustained interaction, not a single bump
- 0 falls in 100k steps — stable locomotion throughout
- 47 ball contact episodes across 5 curriculum stages
- CPG at 40% — the dog was trotting, not sprinting
The 10-seed ablation study confirmed this wasn’t a fluke. Configuration B (SNN + Cerebellum) outperforms the PPO baseline by 3.5× on ball approach metrics, with significantly lower variance.
What This Means
This is not a robot dog playing fetch. It’s a proof of concept for something deeper: a biologically grounded system that develops goal-directed behavior through prediction error minimization, not through reward engineering.
The dog doesn’t get a treat for touching the ball. It touches the ball because touching the ball reduces prediction error. The ball is interesting because the system expects it to be interesting — and the Free Energy framework turns that expectation into action.
Four changes. One minus sign. A robot dog that learned to care about a ball.
MH-FLOCKE is an independent research project by Marc Hesse in Potsdam, Germany. The system runs on a Unitree Go2 quadruped in MuJoCo simulation, using spiking neural networks, a cerebellar forward model, and central pattern generators.
Watch the full run: YouTube Video #3 · Read the paper: aiXiv